tldr: Processing Data Warehousing Queries on GPU Devices
Part of the tldr series, which summarizes papers I'm currently reading. Inspired by the morning paper.
Much research has shown that databases using GPUs have the potential to be much faster than databases using CPUs at the microbenchmarking level. CPUs have a few cores while GPUs can have thousands of smaller cores intended to execute in parallel. However, no major data warehouse (e.g. Teradata, DB2, Oracle, SQL Server, Hive, Pig, Tenzing) truly uses GPUs in production.
The paper investigates why by analyzing query processing using GPUs. Specifically:
The next few sections of this post summarize their main questions and results.

 The above figure shows how PCIe data transfer (in gray), kernel execution (in black), and overall performance (in red) sped up after compressing data for the SSBM queries. PCIe data transfer time always decreases due to less data being transferred.
The above figure shows how PCIe data transfer (in gray), kernel execution (in black), and overall performance (in red) sped up after compressing data for the SSBM queries. PCIe data transfer time always decreases due to less data being transferred.


The Yin and Yang of Processing Data Warehousing Queries on GPU Devices (2013)
Yuan et al.Much research has shown that databases using GPUs have the potential to be much faster than databases using CPUs at the microbenchmarking level. CPUs have a few cores while GPUs can have thousands of smaller cores intended to execute in parallel. However, no major data warehouse (e.g. Teradata, DB2, Oracle, SQL Server, Hive, Pig, Tenzing) truly uses GPUs in production.
The paper investigates why by analyzing query processing using GPUs. Specifically:
- Ying: PCIe data transfer between host memory (CPU) and device memory (GPU)
- Yang: Kernel execution, where the query is executed on device memory data. (A kernel is a function compiled to execute on GPUs.)
The next few sections of this post summarize their main questions and results.
Where does time go when processing warehousing queries on GPUs?

The figure above breaks down the execution time of the SSBM queries. Other (in red) includes things like data structure initialization on the CPU before launching kernels. Most time is spent on PCIe transfer (in black) and kernel execution (in gray).
PCIe transfer is dominated by the amount of data processed from the fact table, since the fact table is so much larger than the dimension tables. This amount of data is determined by the number of fact table columns referenced by the query. Thus, queries in the same flight spend roughly equal amounts of time on PCIe transfer.
How do existing software optimization techniques affect query performance on GPUs?
The authors next investigate 3 software optimization techniques and how they improve (or don't improve) query performance on GPUs:Data compression

Kernel execution speeds up the most for query flight 2 because most of the time is spent on hash probing operations, which can be greatly sped up from data compression.
Other query flights don't benefit at much. For example, query flights 1 and 3's times are dominated by coalesced data accesses, which GPUs can already optimize well. (A coalesced data access is when parallel consecutive threads make consecutive global memory accesses while running the same instruction.)
To understand this technique, here's some background. Host memory allocations are pageable unless otherwise specified. Pinned memory is a temporary page-locked "staging area" which the GPU driver uses to copy host data to device memory, as we can see in the figure below. Pinned transfers are faster than pageable transfers. However, allocating "too much" pinned memory decreases the amount of available memory and reduce overall performance. (How much is too much depends on the system.)
CUDA and OpenCL both support unified virtual addressing. Kernels can directly access pointers in this unified address space. Furthermore, kernels can directly access data in pinned host memory implicitly over PCIe. The authors decided to pin the host memory that stores the fact table's data. The figure below shows how the overall performance is affected:


Transfer overlapping
Transfer overlapping is overlapping kernel execution and PCIe data transfer.To understand this technique, here's some background. Host memory allocations are pageable unless otherwise specified. Pinned memory is a temporary page-locked "staging area" which the GPU driver uses to copy host data to device memory, as we can see in the figure below. Pinned transfers are faster than pageable transfers. However, allocating "too much" pinned memory decreases the amount of available memory and reduce overall performance. (How much is too much depends on the system.)
 |
| Source: https://devblogs.nvidia.com/how-optimize-data-transfers-cuda-cc/ |

In query flight 1, fact tables columns are accessed more than once, so the low PCIe bandwidth cancels out any performance gains from transfer overlapping.
On the other hand, the performance improves when the kernel sequentially accesses many fact table columns, each only once. We can see this in some of the queries in query flights 2 and 3.
However, queries that access more data from dimension tables have random access patterns, and do not improve.
Note: Since this paper was written, the PCIe data transfer bandwidth on the latest GPUs has increased significantly, from 12 GB to ~45 GB. Thus, transfer overlapping is more effective now than before.
Note: Since this paper was written, the PCIe data transfer bandwidth on the latest GPUs has increased significantly, from 12 GB to ~45 GB. Thus, transfer overlapping is more effective now than before.
Invisible Join
Invisible join can improve performance of queries that access more data from dimension tables and thus have a lot of random memory access patterns. It transforms joins on foreign keys into predicates on the fact table. These predicates can then be simultaneously evaluated.
The figure below shows how PCIe data transfer (in gray), kernel execution (in black), and overall performance (in red) changed. PCIe data transfer time stays constant because invisible join does not affect it at all. Queries which access dimension table data have improved kernel execution times.
However, we can see that for a couple queries, kernel execution performance actually becomes worse. This is because those queries do not access the dimension table much, but invisible join increases time spent on selection operations on foreign key columns.

The invisible join technique is not used to improve performance in the paper because it involves heavy reorganization for dimension tables and foreign keys in the fact table, which is not practical for real-world data warehouses.
Under what conditions will using GPUs significantly outperform CPUs when processing warehousing queries?

All SSBM queries run faster on GPU based query engines (in red) than on CPU based query engines (in gray), as we can see in the figure above.
However, the amount of improvement heavily depends on the query type. As shown in the figure below, queries dominated by selection operations or random accesses to dimension tables only speed up by 2x when using GPUs. However, the other queries can take advantage of the data compression and transfer overlapping techniques. Queries 2.1-3, 3.2-4, and 4.1-3 each speed up by 4.5-6.5x.
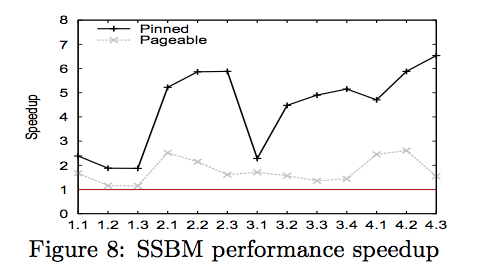
The most important factor is pinned memory: when data is stored in pinned memory (in black), the speedups are a lot higher than when the data is stored in pageable memory (in gray). We can see this in the above figure. This is because data stored in pinned memory can fully take advantage of PCIe data transfer bandwidth.
How would advances in GPU hardware affect query performance?
The authors first ran SSBM queries on 3 generations of NVIDIA GPUs and measured kernel execution times. From the graph below, we can see that the kernel execution time on the GTX 680 is only roughly 10% different from the kernel execution time on the GTX 480, despite an 2x improvement in peak performance from the GTX 480 to 680. Thus, more GPU computational power doesn't lead to much improvement in query performance. Instead, query performance is limited by device memory accesses.


Conclusion
The authors sum up why GPUs haven't been adopted by real-world data warehouses:
- GPUs only substantially improve query performance in specific situations. For example, when:
- Data is stored in pinned host memory.
- Queries aren't dominated by selection operations or random device memory accesses.
- Programming models aren't currently performant or portable enough for data warehouses.
- Improvements in GPU hardware don't lead to correspondingly substantial improvements in query performance.