tldr: Spinnaker

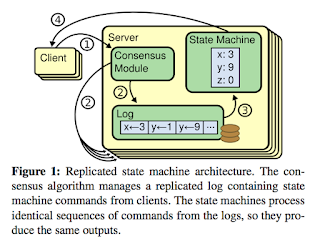
Part of the tldr series , which summarizes papers I'm currently reading. Inspired by the morning paper . Using Paxos to Build a Scalable, Consistent, and Highly Available Datastore (2011) Rao et al. Introduction Spinnaker is a datastore developed at IBM to run on a large cluster of commodity servers in a single data center. This system's features include: Key-based range partitioning 3-way replication Transactional get-put API. Can choose either: Strong read consistency Timeline read consistency Paxos Spinnaker's replication protocol is a variation of the Multi-Paxos protocol . It will be discussed in a further detail later, but for now, here's an overview of Paxos. Paxos solves reaching consensus on a value on 2F+1 replicas while tolerating up to F failures. Once consensus is reached, the value can be accessed as long as the majority of replicas are up. There are 2 phases in Paxos: Leader election Propose . A node that wants to propose a ...