tldr: Raft + Implementation Tips
Part of the tldr series, which summarizes papers I'm currently reading. Inspired by the morning paper.
 Raft divides time in terms of terms. Terms aren't defined by being the same length of time, but by what occurs in each one. A timeline for Raft might look like the below figure:
Raft divides time in terms of terms. Terms aren't defined by being the same length of time, but by what occurs in each one. A timeline for Raft might look like the below figure:






Raft (Extended Version) + Implementation Tips [2014]
Ongaro et al.
Note: For implementation tips, see the end of this blog post.
Note: For implementation tips, see the end of this blog post.
Introduction
Consensus algorithms
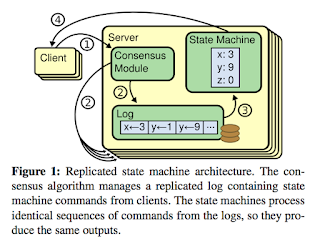
The replicated state machine approach is useful for providing fault-tolerance in distributed systems. It lets a cluster of unreliable machines continue operating even when some of its members fail. In this approach, machines usually use a replicated log to stay in sync. As shown in the figure below, each server's log stores the same commands in the same order. Every state machine executes commands from its own log in order. State machines are deterministic, so each produces the same order of outputs. Once the majority of machines have responded, the command is done executing.

Consensus algorithms ensure that the replicated log stays consistent. In the figure above, clients send commands to a server's consensus module, which adds them to the log. The module also communicates with other servers' consensus modules to make sure every log is eventually consistent (same commands in same order), even when some servers fail. Thus, consensus algorithms ensure:
- Safety. This means never returning incorrect results in non-Byzantine environments, and includes network delays and partitions, and packet loss, duplication, and reordering.
- Availability as long as majority of servers are up and communicating with each other.
Why Raft?
The Raft consensus algorithm was developed in response to the Paxos consensus algorithm because the authors thought Paxos was hard to understand and to build practical systems on top of.
Raft's main goal is understandability: people should be able to easily understand and develop intuition about the algorithm. So, the authors decomposed problems into different stages and reduced the number of possible state spaces. The system also makes leader election an explicit part of the algorithm design.
Raft Algorithm Overview
A Raft cluster is made up of several servers. Each server can be in one of the following states:

Each term is divided into two phases:
- Leader election
- If the leader from the previous term fails or becomes disconnected from the other servers, at least one follower converts to a candidate and tries to become the leader.
- If 1 candidate wins the election and becomes the new leader, we go to the normal operation stage.
- If there's no clear winner, the term ends there and a new term begins. (This happens in term 3 in the above figure.)
- Normal operation
- The elected leader is in charge of log replication. It handles all client requests and sends requests to followers.
- The other servers are all followers. They redirect any received client requests to the leader and passively respond to requests from the leader.
There are also some conditions on the above processes to ensure safety, such that if any server has applied a log entry to its state machine, no other server can apply a different command for the same log index.
As seen in the timeline above, terms are numbered 1, 2, 3... Each server stores what it thinks is the current term number. However, this isn't always the actual current term since servers may fail and miss out on elections or even entire terms. To handle stale term numbers:
- Whenever servers communicate, they exchange current term numbers. If the servers have different term numbers, the server with the smaller term number updates its term number.
- If a candidate or leader realizes it has a stale term number, it immediately converts to a follower.
- If a server receives a request with a stale term number, it rejects the request.
Finally, servers use RPCs to communicate. RPCs are:
- Resent if no response comes on time.
- Sent in parallel for better performance.
There are 2 basic types of RPCs:
- RequestVote RPCs. Initiated by candidates during elections.
- AppendEntries RPCs. Initiated by leaders to replicate log entries and send heartbeats.
In the next few sections, we go into more detail.
Leader Election
Leaders maintain their authority by periodically sending heartbeat messages to all followers. (Specifically, they send empty AppendEntries RPCs.)

If a follower receives no messages from the leader for a period of time, called the election timeout, it begins an election. The follower increments its term, converts to a candidate, votes for itself, and then sends RequestVote RPCs to the other servers. Each of the other servers votes only for the first candidate it receives a RequestVote from.

This process has 3 possible outcomes:
- The candidate wins the election.
- This happens when a majority of the servers vote for the candidate.
- The candidate becomes the leader of the next term.
- Another server wins the election.
- While waiting for votes, the candidate can receive an AppendEntries RPC from another server, which means that server is claiming to be the leader.
- If that server's term is at least as large as the candidate's term, the candidate recognizes that server as the leader.
- The candidate then converts back to a follower.
- A period of time goes by with no winner.
- If there is at least 1 candidate, it's possible that no candidate receives the majority of votes. This is called a split vote.
- Then, each candidate will restart its election timeout and then start a new election.
- To ensure split votes are resolved quickly and happen rarely, election timeouts are chosen randomly from a bounded interval. This ensures that usually only 1 server times out at a given moment.
To keep the algorithm simple, Raft guarantees that all the committed entries from previous terms are already present on each new leader from the moment of its election. A candidate can't win an election unless its log contains all committed entries. To ensure this, we slightly modify the process described above: if a follower who's voting sees from the RequestVote RPC that its log is more up-to-date than the candidate's log, the follower won't vote for that candidate.
Log Replication
The leader receives client requests, which contain commands to be executed. It appends the command to its log and then sends AppendEntries RPCs to the other servers. Each log entry, as seen in the figure below, contains the current term number, its position in the log, and a state machine command.

A log entry is committed when the leader decides it's safe to apply it to its state machine. This happens when the entry is replicated on a majority of the servers. For example, in the figure below, entries 1 through 7 are committed. The leader maintains the highest index it knows that's been committed. In the figure below, that index would be 7. It sends this index in AppendEntries RPCs to followers. Once followers learn that a log entry is committed, it applies the entry to its state machine in order.
 Raft maintains the Log Matching Property:
Raft maintains the Log Matching Property:


- If 2 entries in different logs have the same index and term, then they store the same command.
- Guaranteed because for each log index in each term, the leader creates at most 1 entry. Also, log entries always stay in the same log position.
- If 2 entries in different logs have the same index and term, then the logs are identical in all preceding entries.
- Guaranteed because every AppendEntries RPC that the leader sends includes the previous entry's index and term. The follower rejects the RPC if it doesn't find that previous entry in its log.
Finally, to make sure new leaders commit previous term's entries, Raft never commits log entries from previous terms by counting replicas.
Inconsistent logs
The logs of the leader and the followers can become inconsistent through leader and/or follower failures. A follower may end up missing entries that are in the leader, having extra entries that are not in the leader, or both. We can see this in the figure below:

To solve this problem, conflicting entries in follower logs are overwritten with entries from the leader's log. Specifically, the process is:
- During normal operation, leader maintains a nextIndex counter for each follower, which is the index of the next log entry the leader will send to that follower.
- At some point, a follower's AppendEntries RPC consistency check fails.
- The leader finds the latest log entry that it agrees on with the follower.
- Specifically, the leader decrements that follower's nextIndex and retries the AppendEntries RPC until the consistency check succeeds.
- The leader deletes all entries in the follower's log after that point.
- The leader sends all of its entries after that point to the follower.
Note that the leader never modifies entries in its own log.
Here's one more subtlety: there's no one set of committed entries because the leader dictates what the committed entries should be, and the leader can change. For example, in Figure 7 above, server (f) will not be elected because no other servers will vote for it. This is because all the other servers have logs with more up-to-date last entries.
Why doesn't the leader commit solely entries from previous terms? Take a look at the diagram below.

Here's one more subtlety: there's no one set of committed entries because the leader dictates what the committed entries should be, and the leader can change. For example, in Figure 7 above, server (f) will not be elected because no other servers will vote for it. This is because all the other servers have logs with more up-to-date last entries.
Why doesn't the leader commit solely entries from previous terms? Take a look at the diagram below.

In this example,
- (a). Server 1 is leader. It fails to commit the (yellow) entry from Term 2 in entry 2.
- (b). Server 1 crashes. Server 5 is elected by itself, Server 3, and Server 4 as Term 3's leader. It accepts a different (blue) entry from Term 3 in entry 2.
- (c). Server 5 crashes. Server 1 restarts. It starts replicating the yellow entry again.
At this point, should Raft allow Server 1 to commit the yellow entry? Let's think about what would happen if it were committed.
- (d). Let's say server 1 commits the yellow entry and crashes, and server 5 gets elected as Term 4's leader. Then server 5 will overwrite entry 2 with the blue term, even though the yellow entry was already committed. This is bad!
What should we do instead?
- (e). We do not let the leader commit entries from previous terms alone. Instead, Server 1 must also replicate and commit a (red) entry from the current term (Term 4) in order to commit the yellow entry. At this point, Server 5 can no longer be elected because most of the servers have logs with more up-to-date last entries.
Follower and candidate crashes
If a follower or candidate crashes before responding, future RequestVote and AppendEntries RPCs sent to it are resent indefinitely until the server comes back up.
Timing
Before talking about timing, we define the following terms:
- Broadcast time is the average time it takes a server to send RPCS (in parallel) to every other server and receive responses. It is a property of the system.
- Election timeout is described in an previous section, and is chosen by the programmer.
- MBTF is the average time between failures for a single server.
To remain functional, Raft's leader election must satisfy the following timing requirements:
- Broadcast time should be an order of magnitude less than the election timeout. Then leaders can reliably send heartbeat messages to maintain authority.
- The election timeout should be a few orders of magnitude less than the MBTF. Then Raft can make progress and only be unavailable for around the interval of the election timeout.
If the programmer chooses a value for the election timeout that's too large, then there'll be an unnecessarily long interval after a leader fails and before a new leader is elected. If the programmer chooses a value that's too small, then followers will often time out before the leader has a chance to send an RPC. Thus, a badly chosen value only affects liveness, not safety, of the system.
Cluster Membership Changes
The cluster configuration isn't constant - for example, if servers fail, or if the client specifies that servers should be added or removed for more or less replication. However, we have to careful about electing two leaders in the same term. No atomic approach exists for avoid that. Instead, Raft uses a two-phase approach: it switches to the joint consensus phase, and then to the new configuration.
Joint consensus allows:
Joint consensus allows:
- Servers to transition to the new configuration at different times without compromising safety.
- The client to send requests during the phase.
It combines the old and new configurations such that:
- Log entries are replicated to all servers in both configurations.
- Any server from either configuration may serve as leader.
- Agreement of values requires separate majorities from both the old and new configurations.
Specifically, the steps are:
- The leader receives a request to change the configuration from OLD to NEW.
- The leader stores the configuration for joint consensus as a log entry and replicates that entry as usual. Let's call that log entry JOINT.
- Once a server applies the new configuration entry to its log, it follows that configuration when making future decisions.
- Once JOINT has been committed, the leader creates a log entry creates another log entry called NEW, and again replicates that entry.
- When NEW has been committed, servers still under the old configuration can shut down.
Log Compaction
The log can grow long enough to cause availability issue. In order to discard out-of-date information, Raft uses snapshotting. This is when the current state of the entire system is written to stable storage, and then all the log entries up until that point are discarded.
Specifically, the process is:
- Each server independently takes snapshots of the committed entries in its own log.
- The state machine writes its current state to the snapshot.
- Metadata is also included: the index and term of the last entry in the log that was snapshotted. This is so Raft can check consistency during AppendEntries RPCs.
- Once the server completes writing a snapshot, it deletes all log entries that were snapshotted, as well as prior snapshots, if any.
Note that the leader sometimes sends snapshots over the network to followers that are lagging behind. It doesn't happen often, but sometimes the leader has already discarded the next log entry that it needs to send to a follower. The RPC that the leader sends in this situation is called InstallSnapshot. If the follower receives a snapshot with data that's not in its log, the follower discards and replaces its entire log. On the other hand, if the follower receives a snapshot with no new data, it deletes the log entries in its log that are contained in the snapshot, but keep its log entries that are after.
There are a couple more issues to handle:
- Snapshot frequency. Servers can't snapshot too often, since that wastes disk bandwidth and energy. However, Servers can't snapshot too little, since there might not be enough storage to hold an extremely large snapshot.
- Snapshot write time. Since writing a snapshot could take a long time, it could delay normal operation. Raft's solution is to use a copy-on-write strategy so new updates can be accepted without impacting the writing of a snapshot.
Client Interaction
We wrap up this post by describing how the client interacts with Raft.
- The client sends all requests to the leader. When the client starts up, it randomly connects to a server. If that server is not the leader, it will redirect the client to what it thinks is the most current leader. If the leader crashes later on, the client requests will time out and the client will eventually try connecting to a randomly chosen server.
- A client's request can be executed multiple times. To handle duplicates, clients can assign unique IDs to every command. Then if a server receives a command with an ID it's already executed, it can respond without executing the request.
Implementation Tips
Understanding the paper doesn't necessarily translate to being able to easily implement Raft. Here's a growing list of tips:- Treat Figure 2 in the paper not only as a guide, but as the final say. Don't deviate from it and don't miss points.
- Diagram before you code. Then repeat. Keep on redrawing diagrams and rewriting code.
- Here is the diagram I drew before the paper when I thought I understood the paper fairly well:

- And here is the diagram I drew when I coded a working implementation of Leader Election and Heartbeats in Go after 3 code rewrites:

- Adding on to the last bullet point - don't be afraid to rewrite your implementation. Each rewrite will be cleaner and less buggy.
- State changes should be atomic even if new messages come in.
- Take time killing old processes. (For example, in Go, if you want to convert from a follower to a candidate, you don't have to kill the old follower goroutine ASAP.)
- However, apply new state changes immediately. (In Go, if you're converting to a candidate, don't spin off a goroutine for the candidate function. Just call it directly.)
- Separate timer loops and state implementations.
- Use buffered channels to send less RPCs. (The close() function is especially helpful!)


