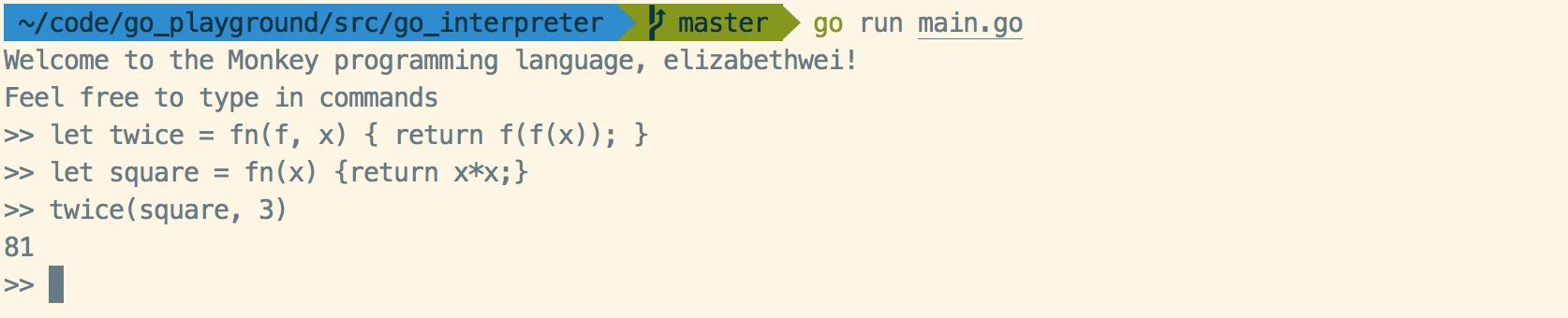
Building A Toy Language Interpreter in Go
In this post, I'll be giving a high-level overview of interpreters, why they're interesting, and how they work. I'll be referencing my repo, go_interpreter, which is a simple interpreter written in Go for a toy language. The figure below shows the structure of our interpreter with an example input:

 In contrast, a compiler first takes in a source program and translates it to an executable machine code target program. Then, the user can pass in inputs to this target program and get outputs.
In contrast, a compiler first takes in a source program and translates it to an executable machine code target program. Then, the user can pass in inputs to this target program and get outputs.
 In general, an interpreter is better at reporting errors since it's processing statements one at a time, and a compiler is faster at generating outputs from inputs.
In general, an interpreter is better at reporting errors since it's processing statements one at a time, and a compiler is faster at generating outputs from inputs.
In this post, we're going to go over a simple interpreter that is capable of supporting:


What is an interpreter?
An interpreter is a language processor that seems to directly execute the source program on user input:

In this post, we're going to go over a simple interpreter that is capable of supporting:
- integers, booleans, strings, arrays, hashmaps
- prefix, infix operators
- index operators
- conditionals
- global and local bindings
- first class functions
- return statements
- closures
You can reference the code I pushed to my repo and run it with the command go build -o toy && ./toy -engine=eval:
You can also turn on logging by setting PRINT_PARSE and PRINT_EVAL to true in parser.go and evaluator.go respectively:
The interpreter is mainly composed of a lexer, a parser, and an evaluator. I copied the structure of our interpreter again:

The output of let x = 5; is nil since it's just assigning 5 to x.
The Lexer
The lexer translates source code to tokens. You can think of tokens as small data structures: "foo" and "bar" are STRING tokens, and "==" is an EQ token, for example.
Note the skipWhitespace() function in lexer.go - our toy language doesn't give meaning to whitespace like tabs or spaces or newlines. Other than that, lexer.go is a pretty straightforward piece of code that just advances through the input and assigns tokens as it goes.
The next step of our interpreter, the parser, will only call the NextToken() function in lexer.go, which just returns the next token.
The Parser
The parser translates tokens from left to right into an AST. AST stands for abstract syntax tree, and it's just a data structure that represents our input. It's the red tree in our diagram of the interpreter above.
Our parser is simple and intuitive - it's a top-down parser, so it builds a parse tree from the root to the leaves. (In contrast, a bottom-up parser builds a parse tree from the leaves to the root.) We can use it for our toy language, which is LL(1). What does that mean?
- Our toy language is LL(1) because it can be generated by an LL(1) grammar.
- An LL(1) grammar:
- Scans the input from Left to right
- Produces a Leftmost derivation (expanding the leftmost variable first each time)
- Uses 1 input symbol of lookahead when making parsing decisions
We can also have LR(k) parsers. This just means:
- Scans the input from Left to right
- Produces a Rightmost derivation in reverse
- Uses k input symbols of lookahead when making parsing decisions
LR parsers can immediately detect syntax errors when scanning the input left to right. LR grammars can also describe more programming languages than LL grammars can. One popular variant of LR that you might see is LALR, which stands for "lookahead-LR". Since LALRs have lower memory requirements, they are used in practice often.
However, an LL parser is simpler to implement by hand, so that's what we chose for our interpreter.
The Evaluator
The final component of our interpreter is our evaluator. This takes our AST and gives the nodes meaning. We use a tree-walking technique, without preprocessing or compiling, for simplicity. Note the Eval() function in evaluator.go - it's the recursive function that walks our AST.
We also have built-in functions, like len for arrays and strings, and tail for arrays (similar to cdr in LISP). We define these in a map, and add BuiltIn as an option in evalIdentifier()'s and evalFunction()'s switch statements.

